【Go 语言设计与实现】 笔记 — Mutex 源码分析

前面几天看完 Channel 之后,意识到 Channel 在目前版本本质上还是一个加锁的 FIFO 消息队列。不管是对 Channel 进行发送、接收还是关闭操作,都会加锁。由此让我想再重新好好看下目前 Golang 的锁实现,以后分析并发性能的时候能够更加清晰。
左书祺老师的《Go语言设计与实现》 在 【6.2 同步原语与锁】一章中详细介绍了 sync.Mutex 与 sync.RWMutex ,按照之前的模式会基于这些内容进行代码阅读梳理和补充,但这次章节安排上将不参照原书,原因主要有两点:
- 书中提到的锁(
sync.Mutex)事实上是标准库sync提供给开发者使用的同步原语,Go 自己 runtime 使用的锁事实上是lock/unlock函数(src/runtime/lock_sema.go,src/runtime/lock_futex.go),在实现上与Mutex.Lock/Mutex.Unlock是不同的,所以会先讲这个(这个其实反而比较sync.Mutex还更加简单一点) - 书中没有介绍
runtime_SemacquireMutex、runtime_Semrelease的具体实现,事实上要理解sync.Mutex,信号量实现是逃不掉的,而且这部分也比较复杂,因此会先分析这两块的源码。
虽然我目前用的电脑是 Windows 操作系统,但本文将主要围绕 Linux / x86 架构的系统平台来介绍 lock 相关 Go 代码以及汇编源码,毕竟大部分服务器还是 Linux / x86 。
基于阅读的 Golang 源码版本是 1.16 ,这篇文章更多是自己对于 Golang Lock 相关源码的学习与梳理,可读性比较差,里面可能存在较多错误,如果有老板觉得有问题请及时反馈,多谢!
目录
1. runtime.lock 与 unlock
其实 runtime.lock 与 unlock 在前文的【计时器】与【Channel】源码分析中已经出现过好几次了,如 addtimer(t) 在操作四叉堆 timers 之前会调用 lock(&pp.timersLock) 锁上 pp.timersLock;在 channel 正式跑发送(chansend)与接收(chanrecv)的代码之前,会调用 lock(&c.lock) 锁上 c.lock。这里的 pp.timersLock 与 c.lock 都是 runtime 内部的类型 mutex(src/runtime/runtime2.go):
1 | // Mutual exclusion locks. In the uncontended case, |
抛开 lockRankStruct (锁排序默认关闭),这里主要用到的字段就是 key ,看注释说明在不同平台的锁实现中,key 的作用是不同的,在信号量实现中 key 会作为 M 的指针指向等待锁的 M, 在 futex 实现中 key 就单纯是个 key。
这里通过注释也可以看到,lock 在 golang 中基于不同操作系统有不同的实现,在 runtime 源码文件夹下也可以看到以 lock_ 为前缀的三个文件,对应不同操作系统的实现:
lock_sema.go基于操作系统信号量系统调用实现的锁,支持的操作系统有:aix、darwin、netbsd、openbsd、plan9、solaris、windowslock_futex.go基于 Futex 实现的锁,支持的操作系统有:dragonfly、freebsd、linuxlock_js.go目标为 JS 及 WebAssembly 平台的实现。
由于之前也提到本文包括后续分析都以 Linux / x86 平台为主,因此我们主要看 lock_futex.go 的 lock 与 unlock 源码。
1.1 lock2
我们先看 lock 的:
1 | const ( |
这里列出了 lock() 函数的调用相关函数,以及有关的一些常量。
可以看到主要实现逻辑都在 lock2 里,在开头函数会调用 getg() 获取当前 g,并基于 g 找到对应目前绑定的 M,累加其 locks 字段 gp.m.locks++
然后就是 “Speculative grab for lock” 尝试性地获取锁:v := atomic.Xchg(key32(&l.key), mutex_locked)
注意这里的 atomic.Xchg (src/runtime/internal/atomic/atomic_amd64.go 对应 x86 64位架构)是个交换值原子操作:
1 | func Xchg(ptr *uint32, new uint32) uint32 |
这里的 atomic 包是在 src/runtime/internal ,是 runtime 内部使用的原子操作函数,而 atomic.Xchg 第一个参数 ptr 是指针,指向交换值目标的内存地址,而第二个参数是用来交换的新值。
值得注意的是返回值,返回的是 ptr 指向的地址中交换前的值,我们可以看下 atomic.Xchg 对应的汇编代码(src/runtime/internal/atomic/asm_amd64.s):
1 | TEXT runtime∕internal∕atomic·Xchg(SB), NOSPLIT, $0-20 |
这里的 XCHGL 即值交换指令,将 AX 寄存器的值与 BX 作为指针指向的地址中的值交换,这时候 AX 持有的就是 ptr 指向地址里的原始值,后续就通过 MOVL 将 AX 的值放到栈帧 16(FP) 对应 ret 返回值。
所以回到 lock2 函数,变量 v 得到的就是 l.key 指向的交换前的原始值,也就是变更前的锁状态(注意不管之前 l.key 是啥状态,这时候都被交换成了 mutex_locked)。
在交换了之后,我们通过条件语句判断 v 进而判断 l.key 之前的状态,如果锁之前的状态是解锁状态(mutex_unlocked),那么就说明我们这次拿到了锁,直接返回。
如果 v 的值不是 mutex_unlocked ,说明锁处于的状态不是解锁状态,可能是 mutex_locked 或 mutex_sleeping ,这都意味着当前线程需要等待解锁,这时候就走到后面等待的逻辑了。
这里有个操作,是 wait := v,源码还给了大段注释说明:如果我们将 l.key 对应的锁状态从 mutex_sleeping 改为其他状态,我们一定要在返回前将它改为 mutex_sleeping 。这句话刚开始看的时候有点让人困惑,等后面分析整体锁的状态变更情况的时候就更容易明白了。
这里的等待是一个大的无限 for 循环,里面分为三种等待方案:
第一种方案是自旋(spinning),自旋只有在多处理器(ncpu > 1)的机器上才会开启,若开启,则代码进入一个小循环(for i:=0; i < spin; i++),在预设的自旋循环周期(active_spin)内,函数会反复查看 l.key 对应的锁状态是否变成了 mutex_unlocked ,如果是则通过 atomic.Cas 更改锁状态为 wait (注意这里是 wait 而不是直接是 mutex_locked) ,并退出 lock2 函数。在这个过程中,如果每次循环发现状态仍然没有解锁,就会调用 procyield(active_spin_cnt),procyield 函数在书中也介绍过,我们再看下对应的汇编(src/runtime/asm_amd64.s):
1 | TEXT runtime·procyield(SB),NOSPLIT,$0-0 |
这里的汇编就是循环调用 PAUSE 指令,在等待循环中插入 PAUSE 指令可以减少处理器的功耗,因为它提示处理器当前线程正在忙等待,可以减少对执行资源的占用。 这里的循环调用次数就是传入的 active_spin_cnt ,也就是 30。
提一下我们更新的值 wait,如果是一般情况,也就是后面不进入 sleeping 的情况,那么我们进入第一种方案的时候,wait 作为之前 l.key 状态的值就是 mutex_locked (排除了 mutex_sleeping),所以用 wait 更新就代表当前线程获得了这个锁,所以没有啥问题,后面 sleeping 的状态我们再具体分析。
如果自旋的循环结束,当前线程仍然没拿到这个锁,那么就会进入第二种等待方案,osyield 调度,让出线程。
第二种方案的模式几乎和第一种自旋是一样的,循环 passive_spin 次(虽然默认 passive_spin 值为 1)查看 l.key 对应锁状态,然后如果是 mutex_unlocked 解锁了就通过 atomic.Cas 更改锁状态为 wait 的值。如果仍然锁着,则调用 osyield。
osyield 在 Go 调度器相关代码中也频繁出现,对应的就是线程让出处理器的系统调用,我们可以看下汇编源码(这里我们看的是 x86 64位 Linux 操作系统对应的源码,src/runtime/sys_linux_amd64.s):
1 | TEXT runtime·osyield(SB),NOSPLIT,$0 |
这里可以看出 osyield 调用了 Linux 系统调用 sched_yield,该 syscall 使线程让出了处理器,使得操作系统可以调度其他线程运行。让出的线程将被放入可运行队列的末尾,等待再次被调度。
而当第二种方案的循环结束,当前线程如果还没获得这个锁,那么这时候就到了第三种方案,调用 futex 进入休眠(sleeping)。
这部分代码看着也比较直观, 首先就是通过 v = atomic.Xchg(key32(&l.key), mutex_sleeping) 将当前状态设为 mutex_sleeping, 然后通过 v 查看锁之前的状态是否为 mutex_unlocked ,如果是则直接退出函数返回(注意这时候这里没有调用 futexsleep 就退出了,但锁状态是 mutex_sleeping ,结合后面 unlock 的逻辑是会让人有些困惑,后面会专门讲)。
再之后,就是 wait = mutex_sleeping(这个赋值挺神奇的,后面状态会讲),然后调用 futexsleep 使线程进入休眠。
让我们看下 futexsleep 的代码:
1 | // Atomically, |
这里的 futexsleep 调用了 futex 对应 FUTEX_WAIT_PRIVATE 操作,如果 val 的值与 addr 地址指向的值相等,那么线程就进入休眠。这里的 ns = -1时,就代表无限时间休眠,直到被手动调用唤醒。
到这里我们把 lock2 代码都过了遍,乍看好像挺好的没问题,但事实上 mutex_sleeping 状态的设置是有点弯弯绕绕在里面的,后面的状态分析我们会讲几个线程并发竞争锁的场景,看看 lock2 这段代码处理有没有问题。
1.2 unlock2
1 | func unlock(l *mutex) { |
unlock 的主要逻辑也类似地,在 unlock2。
函数一开始就不论 l.key 对应锁状态是啥就调用 atomic.Xchg 将其互换为 mutex_unlocked, 然后判断互换前的锁状态值 v:
- 若 v 为
mutex_unlocked,则说明解锁了一个已经解锁了的锁,直接抛出异常。 - 若 v 为
mutex_sleeping,代表可能有线程进入了休眠, 便调用futexwakeup(key32(&l.key), 1)尝试唤醒线程。
看一眼 futexwakeup 的代码:
1 | // If any procs are sleeping on addr, wake up at most cnt. |
第二个传参 cnt = 1 代表这次要尝试唤醒的数量,这里 futex 对应的返回值如果小于 0,代表是调用出错,如果大于等于 0,代表的是这次调用成功唤醒的线程数(详情可参考 Futex 文档 - RETURN VALUE),值得注意的是,futex 的 FUTEX_WAKE_PRIVATE 操作如果没有成功唤醒线程不会报错,而是返回值 0 ,这在后面分析锁状态时也会提到。
判断完 mutex_sleeping 之后,函数会获取当前 g,找到对应 M 减去 gp.m.locks , 同时恢复抢占调度配置 gp.stackguard0 = stackPreempt。
1.3 锁状态分析
前面两小节我们把 lock2 与 unlock2 的代码过了一遍,乍看还是比较直观的,但有些复杂的是 l.key 对应状态的设置,仔细去想想的话是有点让人困惑的,特别是加入了 mutex_sleeping 状态的场景。下面盘几个锁竞争的场景,看看目前的 lock2 与 unlock2 的代码是不是 OK。
1.3.1 场景一: 无 mutex_sleeping
如果我们假设所有的线程获得锁之后,在其他线程进入休眠之前就释放了锁,也就是锁永远不会进入 mutex_sleeping 状态,那么 wait 只可能是 mutex_locked 状态,等待的线程在发现锁状态被占有锁的线程通过 unlock 释放(mutex_unlocked),会立刻将锁状态置为 mutex_locked ,视为获得锁后退出函数。
这个过程不管有多少线程在等待,都是没有问题的,atomic.Cas 是个原子操作,会确保即便有多个线程发现 l.key 的值变为 mutex_unlocked ,也只有一个线程能够成功比较交换到值,视为获得锁。而正常的 lock 与 unlock 使用流程,只有获得锁的线程会在完成自己的工作后调用 unlock 变更锁状态为 mutex_unlocked。
1.3.2 场景二:考虑 mutex_sleeping ,两线程
如果线程在等待的过程中通过 futex 进入了休眠状态了,那么锁状态的变更就变复杂一些了。我们先考虑两个线程的情况,也就是一个线程 A 获得锁后在忙,另一个线程 B 在等待过程中进入了休眠。
在这个时候,线程 B 代码是在 lock2 的 futexsleep(key32(&l.key), mutex_sleeping, -1) 进入的休眠,这个时候, wait = mutex_sleeping ,而 l.key 指向的状态也被线程 B 设为了 mutex_sleeping 。
然后我们假设线程 A 忙完了,调用 unlock 释放锁,这时候在 unlock2 会先将 l.key 指向的锁状态置为 mutex_unlocked , 然后通过 v 得知之前的状态是 mutex_sleeping , 因此根据判断会调用 futexwakeup 唤醒休眠的线程,在这里就是线程 B。
线程 B 被唤醒后,继续执行 futexsleep 后面的代码,它会再一次开始循环,这时候它在自旋时很快发现 l.key 对应状态为 mutex_unlocked,因此它会调用 atomic.Cas(key32(&l.key), mutex_unlocked, wait) 并退出函数,注意这个时候 wait 为 mutex_sleeping ,因此线程 B 获得锁之后,锁状态为 mutex_sleeping。
等线程 B 忙完后调用 unlock 释放锁,会将 l.key 指向的锁状态置为 mutex_unlocked,同时通过 v 得知之前的状态是 mutex_sleeping ,因此会再调用 futexwakeup,这时候会发现没有等待休眠的线程了,函数退出后,整个流程就结束了。
我自己推演的时候觉得线程 B 获得锁之后进入 mutex_sleeping 状态,而且 unlock 之后明明没有线程休眠了还调用了一次 futexsleep ,这么弄是不是多此一举,还以为是自己搞错了。后面考虑到更多线程的休眠等待情况,可能这是通过一个状态来控制多线程休眠等待锁的一个解决方案逻辑。
1.3.3 场景三:考虑 mutex_sleeping,三线程,两休眠
让我们考虑下线程 A 在忙,线程 B、线程 C 休眠的情况,前面的流程几乎和 1.3.2 是一样的,直到线程 B unlock , 线程 B unlock 时会通过 futexsleep 唤醒线程 C,因为它获得的锁状态是 mutex_sleep ,而线程 C 则像 1.3.2 的线程 B 一样,重复进入循环,在发现 mutex_unlocked 之后获得锁,同时把 l.key 状态置为 mutex_sleeping。
这里可以发现,留下线程 B、C 通过将 wait 置为 mutex_sleeping 就是留了个尾巴,在自己获得锁了之后将 l.key 状态置为 mutex_sleeping ,在自己 unlock 之后看到这个 mutex_sleeping 尝试唤醒下一个休眠的线程,这个线程可能有也可能没有,但如果有那么这一次尝试唤醒就唤醒了,这也是一连串操作的意义。
感兴趣的老板可以试一下其他场景,比如三线程在线程 C 没有进入休眠,这时候线程 A unlock 时候的推演,你会发现线程 C 会比线程 B 更先获得锁,因为在 A unlock 的时候,A 拿到的状态是被 C 设置的状态 mutex_locked,被线程 B 原先设置的 mutex_sleeping 被线程 C 交换了放在了它自己的变量 v 与 wait 里,所以 A unlock 的时候不会调用 futex_wakeup , 等到线程 C 拿到锁的时候,状态又会被线程 C 设置成 mutex_sleeping
1.4 顺带一提:lock_sema 的 lock2 实现
这里顺带提一个 lock_sema.go 基于信号量的锁实现,因为这个实现对于 l.key 的操作比较神奇,我们看代码(src/runtime/lock_sema.go):
1 | const ( |
这里可以看到,信号量实现的锁 lock2 在前面和 futex 实现是差不多的,都是先自旋,再调用 osyield 调度等待,不同的地方在于它的 Cas 操作:
atomic.Casuintptr(&l.key, v, v|locked)在获得锁的时候是通过或位运算将 &l.key 赋上locked(值为 1)atomic.Casuintptr(&l.key, v, uintptr(unsafe.Pointer(gp.m))|locked)休眠部分的逻辑,会在&l.key整上uintptr(unsafe.Pointer(gp.m))|locked,就是 gp.m 的指针和 locked 状态的或运算gp.m.nextwaitm = muintptr(v &^ locked)通过从 v 或者说从l.key获取状态,去掉第一位 locked,变成 m 指针赋值给gp.m.nextwaitm。
我看到这部分代码,一开始很想不通的一点是,为什么 &l.key 可以被在最低一位随意设置 locked 状态,如果 &l.key 存的 m 的地址最低位为 1, 那么做 v &^ locked 操作时候不是会被置成 0,地址不是出错了吗。
后来我琢磨明白了,&l.key 存的 M 结构体地址最低位不可能是 1 ,因为 m 结构体的内存对齐(alignment),看了下 m 的类型定义,作为结构体应该是它的地址应该是 8 字节对齐的(m 的第一个字段为 g0 是 *g 类型,是个指针),所以 m 的内存地址应该二进制最低 3 位都会是 0 ,也就意味着只要 &l.key 在解引用作为 m 指针使用前,这最低三位可以随意使用,作为锁状态维护也没问题,在作为 m 指针使用时记得把最低位置 0 就 ok。
自己做上层应用开发的,头次见到这种玩法没见过世面,想明白之后感觉还挺神奇的,有点 C 里 union 的味道了。
1.5 总结
我们梳理了 runtime 中 lock 与 unlock 这两个主要的内部锁函数,其实看得出来本质上内部的锁等待就是自旋+让出调度+系统调用休眠三步走,锁状态的变化有点没那么直观,不过我想主要也是希望通过一个字段来控制多线程并发竞争休眠对应状态的一个设计吧。
2. runtime_SemacquireMutex 与 runtime_Semrelease
runtime_SemacquireMutex 与 runtime_Semrelease 都是对应 runtime 的信号量实现。我在读这段代码的时候是没想到这部分信号量的实现是涉及到数据结构的(平衡树 - 树堆),所以在介绍这部分代码的时候也会稍微讲下树堆这个数据结构。
这两个函数的定义在 src/sync/runtime.go:
1 | // SemacquireMutex is like Semacquire, but for profiling contended Mutexes. |
对应实现可以在 src/runtime/sema.go 找到通过 go:linkname 链接的对应实现的函数:
1 | //go:linkname sync_runtime_Semrelease sync.runtime_Semrelease |
可以看到实际实现的函数为 semacquire1 与 semrelease1,下面我们就分开重点讲这两块:
2.1 semacquire1
关于 semacquire1 的入参,profile 与 skipframes 分别用于 profile 和 trace,不是本次重点就不分析了。另外两个入参,addr 即存有指向“信号量”的指针, lifo 是一个标识,如果这次进入的 goroutine 等待信号量,那么它在进入队列是进入队首还是队尾(FIFO 还是 FILO 的)。
1 | func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) { |
整体代码可以分为 easy case 和 hard case,这里面涉及到了一个重要的结构体 semroot ,它是一个树堆实现的平衡树,用来维护整个 runtime 等待信号量的 goroutine。
我们先看 easy case
2.1.1 easy case 与 cansemsacquire
easy case 很简单,就是调用 cansemsacquire,如果返回 true 就直接退出函数,我们直接来看下 cansemsacquire:
1 | func cansemacquire(addr *uint32) bool { |
函数逻辑也很简单,就是看 addr 指向的值是不是 >0,如果为 0 直接退出返回 false,不然则对应值 -1,返回 true。
这个条件就是快速判断目前有没有信号量可以获取,后面 cansemsacquire 还会被调用好几次,就是看整个 semacquire1 运行过程中是不是有信号量被 release 了(对应 semrelease1),这样就不需要把 goroutine 加入到 semroot 里等待了,可以直接获取信号量返回。
2.1.2 semroot 与 treap
我们看下后面 hard case 的代码, 开始函数会调用 acquireSudog 封装一个当前 goroutine 对应的 sudog 结构体给到 s。 关于 acquireSudog 我在前面分析 channel 的时候专门讲过,这里不再分析了。
接着就是 root := semroot(addr) 我们重点来掰扯这个 semroot(src/runtime/sema.go):
1 | func semroot(addr *uint32) *semaRoot { |
首先,semroot 函数根据传入的 addr 值经过取模(semTabSize)后作为 semtable 的下标返回对应的 semaRoot 结构体。 而 semaRoot 管理着一个维护 sudog 的平衡树,而这里使用的平衡树,semaRoot 的字段暗示了:就是 treap(树堆)。
树堆是一个平衡二叉树,每个节点会维护两个值,一个值(val)代表树真实维护的值,这个值在树堆中与各节点保持二叉搜索树的性质(任意父节点的值大于左子节点的值,并小于右子节点的值),而另一个值(ticket)是随机生成的,与各节点保持堆的性质(这里用最小堆,即任意父节点小于其任意子节点的值)。
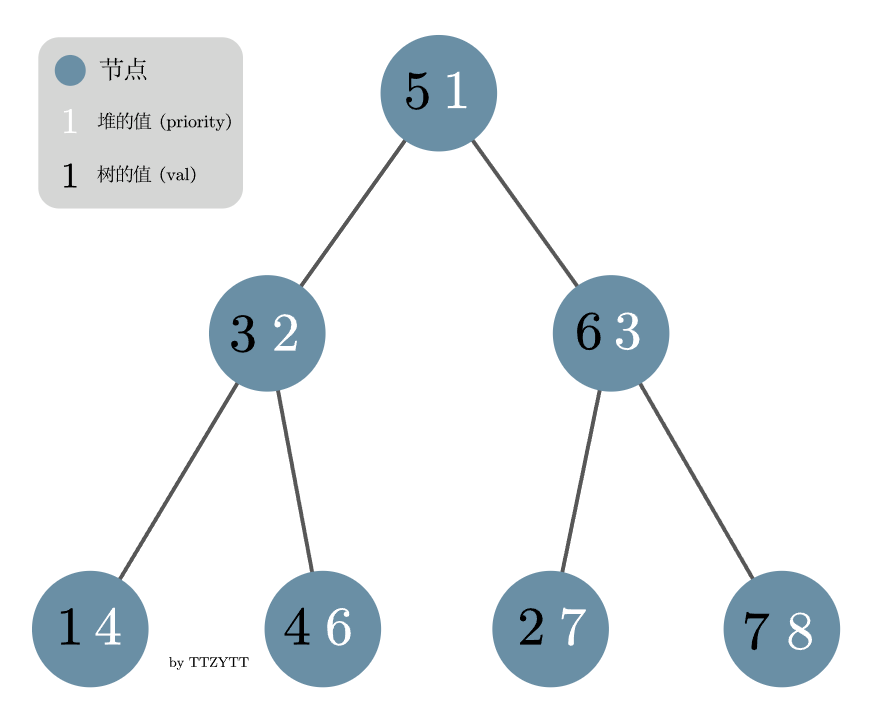
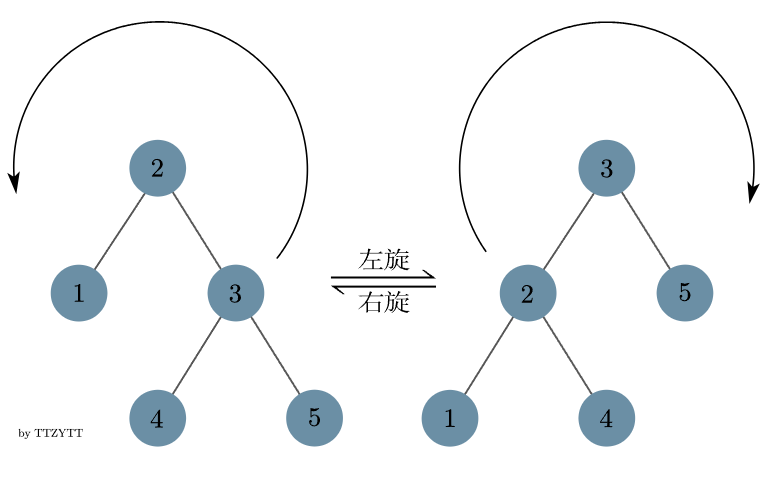
树堆会基于节点 ticket 的值,使用旋转操作(左旋与右旋)来维护整个平衡二叉树,详细可以看 OIWIKI 关于树堆旋转操作的介绍,这里说点自己的感悟:左旋与右旋,在维护堆性质的同时(使子节点上移)又不破坏二叉搜索树的性质,然后使整个树更平衡了,还是很神奇的,下面是 rotateLeft 与 rotateRight 的源码和操作图示,可以简单看下:
1 |
|
在 semaRoot 中,对应树堆实现的主要逻辑就是 semaRoot.queue 与 semaRoot.dequeue 两个方法,代表树堆的添加新节点与删除指定节点,我们来分别看一下,首先是 queue:
1 | // queue adds s to the blocked goroutines in semaRoot. |
queue 主要逻辑就是基于二叉搜索树的规则从 root.treap 为根查找整个树堆有没有 addr 地址本身这个值 ,如果找到了这个值以及对应的 sudog ,则把入参的 sudog 加入到这个对应 sudog 的 waitlink 中(根据 FIFO 选项来决定新加入放在 waitlink 的链表头还是尾)。
值得注意的是,这里的变量 pt 是一个二级指针,即它的类型是 **sudog (我看这段源码的时候理解了好一会儿才意识到),之所以 pt 是二重指针而不是直接的 *sudog 指针, 是因为整个二叉搜索过程,pt 操作的对象都是各个结构体维护的 *sudog,作为二重指针它可以不涉及复制结构体的情况下更好地修改更新各个 *sudog 指向的 sudog。各位感兴趣的自己可以画图感受下 pt 整体运作的过程。
如果在现有树堆中没有找到 addr 值,那么就以最后查看的树堆节点为父亲节点,把我们入参 sudog 的 ticket 字段通过随机数生成(这里的 fastrand 使用了 xorshift 伪随机生成算法),加入到树堆中。
然后我们开始我们新加入作为叶子的 sudog s 开始判断其与其父节点是否符合最小堆的性质:s.parent.ticket 是否小于 s.ticket ,如果不是,那么若 s 是左子节点,就执行针对 s.parent 的右旋操作,若 s 是右子节点则执行针对 s.parent 的左旋操作。
执行完旋转操作之后,s 其实已经上移到了原来 s.parent 的位置 ,因此我们的循环仍然会判断 s.parent.ticket 与 s.ticket 的大小,看看是不是要重复上面的旋转操作,然后通过循环逐步向上判断节点,直到到达树的根。整个过程中通过旋转,使得整个树更加平衡了。
我们再看下 dequeue 部分的逻辑:
1 | // dequeue searches for and finds the first goroutine |
和 queue 类似,dequeue 函数也是通过 ps 这么一个二级指针按照二叉搜索树的逻辑去搜索整个树堆,查找树堆里有没有值为 addr 的节点,如果有直接 goto 跳到 Found 标签,s 作为被找到的节点承接接下来的出队操作。如果搜下来发现没有就直接退出函数了。
再看 Found 部分,找到了之后先看 s.waitlink 里有没有 sudog ,如果有的话说明整个节点不需要被删除,弹出一个 sudog 就可以,所以就会把 s 对应的 sudog 拿出来作为返回值,把队首 s.waitlink(t) 的 sudog 替换到原先 s 在树堆里的位置。
然后我们看 s.waitlink 为空没有 sudog 的情况,这时候我们就需要把 s 所在的节点删除掉,核心操作是看 s 是不是树堆的叶子节点,如果是就直接删除,如果 s 不是叶子节点,就逐步旋转将 s 节点下移(如果只有左子节点则右旋,反之则左旋),直到 s 变成一个叶子节点。
树堆的优势就是相当于红黑树等平衡树实现非常简单,而且同时在一般情况下能够较好保持树的平衡性,整体查询、删除、插入操作的时间复杂度都在 logN。
下面我们再回过头看 semacquire1 接下来的代码。
2.1.3 harder case
除掉 profile 部分的代码, semacquire1 接下来的代码就是一个 for 循环:
1 | for { |
我们按顺序看接下来循环内的每一步:
- 给
root.lock加锁(lockWithRank的逻辑对应前面runtime.lock2的逻辑,可以看前面章节) root.nwait += 1, 代表这个信号量等待的 goroutine 数量加一- 然后调用
cansemacquire尝试一下获取信号量,如果能获取到就退出循环(循环外释放sudog),没获取到走接下来流程 - 前面尝试获取不到,那么函数就会调用
root.queue将基于addr本身地址的值将s这个sudog加入到树堆treap里,同时也传入lifo参数,来决定这个sudog是先进先出还是先进后出的。 - 加入作为等待队列的树堆之后,函数调用
goparkunlock,这是一个和gopark类似的函数,本质会让当前 goroutine 与 M 分离,M 继续找 goroutine 调度, 具体代码稍后讲一下 - 后面的代码是 goroutine 被唤醒被调度之后的代码,这时候再判断,如果
s.ticket != 0或者cansemacquire(addr),那么代表获取到了信号量,则break退出整个循环 - 如果这时候还没退出循环,说明在之前没有获取到信号量,这可能是在 goroutine 被唤醒的过程中信号量被别的协程抢去了,所以再一次循环走一遍之前的流程
我们现在看下 goparkunlock 的源码(src/runtime/proc.go):
1 | // Puts the current goroutine into a waiting state and unlocks the lock. |
gopark 函数在之前 channel 的源码分析已经讲过了 ,在 channel 的实现中,被分离的当前 g 是被放在了 channel 的 waitq 里(sendq 与 recvq),而这次信号量的实现里等待的 g 是被放在了 semaRoot 的树堆里,等待后续 Semrelease 时候被唤醒。
退出循环后,函数会调用 releaseSudog 把 sudog 释放,之前 channel 分析里也提到过。
总结来看,整个 semacquire1 和之前分析过的通道发送函数 chansend 有相似的地方,也涉及到 goroutine 的调度,这也是为啥之前在 channel 分析的时候有部分 sudog 的字段没分析到,这部分其实就是 semaRoot 维护树堆用到的,比如 ticket、waitlink 与 waittail
2.2 semrelease1
看完 semacquire1 ,我们看对应的 semrelease1 操作的源码。
1 | func semrelease1(addr *uint32, handoff bool, skipframes int) { |
看过 semacquire1 之后,理解 semrelease1 就比较方便了。 下面我们快速过下 semrelease1 直到 root.dequeue 为止的整个流程:
- 给
addr地址指向的值加 1 ,相当于信号量加一,代表 release 过程 - Easy case:函数会看一眼
root.nwait, 看看有没有等待的 goroutine,如果nwait = 0,代表目前没有 goroutine 在等待队列需要我们唤醒的,那么函数直接退出 - 给
root.lock加锁,准备开始唤醒等待的 goroutine,在加完锁后再看一眼root.nwait是否为 0 ,因为 lock 的时候是有可能阻塞等待获取锁的。如果root.nwait为 0 直接解锁退出。 - 调用
root.dequeue获取等待的sudogs - 如果
s != nil,说明获取到了一个等待的 goroutine,这时候给root.nwait += 1,代表释放信号量。
做完这些之后,函数会给 root.lock 解锁(接下来的操作会比较耗时,但已经和 root 没有关系了)。
如果 s != nil ,函数会看看入参 handoff 是不是为 true,代表是否要进入 handoff 模式。如果 handoff = true ,那么函数就会这个条件判断语句中执行 cansemacquire(addr) 尝试获取信号量,如果成功获取,上面两个条件都成立,函数会将 s.ticket 赋值为 1。
乍看这个 cansemacquire(addr) 以及 s.ticket = 1 的操作很奇怪,但这个要结合 semacquire1 的语句一起看,在 semacquire1 的 gounlockpark 之后,有退出循环的条件判断:
1 | if s.ticket != 0 || cansemacquire(addr) { |
这里的 s 对应 dequeue 弹出的 sudog ,我们看 dequeue 源码就知道 s 在 dequeue 其 ticket 字段是会被置 0 的,而只有在 semrelease1 里 handoff = true 且 cansemacquire(addr) 成功时,这个 s.ticket 会被置 1。semrelease1 如果开启 handoff, 这里 cansemacquire 就起到了一个提前获取信号量的作用,不然后续操作较长很可能这个信号量被别的 goroutine 拿走。而在 semacquire1 里 goroutine 被唤醒后,看到 s.ticket != 0 ,也不会尝试调用 cansemacquire 获取信号量了,因为前面 handoff 已经获取过了。handoff 在本节最后统一分析一下。
在 handoff 的条件判断之后,就是调用 readyWithTime(s, 5+skipframes) ,我们看下这个函数的源码:
1 | func readyWithTime(s *sudog, traceskip int) { |
本质上就是调用 goready,我们在 channel 一节中已经分析过 goready ,它会将传入的 sudog 对应的 goroutine 设置为 Grunnable,并加入到当前 P 的 runq 运行队列中(并且是在队首),并尝试唤醒一个空闲的 P 使其进入自旋状态寻找可以运行的 goroutine。
到这里整体 semrelease1 的逻辑就理得差不多了,还剩一个 handoff 开启的情况,在 goyield 调用的源码注释其实介绍了 handoff: 就是当 handoff = true 时,函数会调用 goyield 使当前运行的 goroutine 让出处理器控制权,由于之前调用了 readyWithTime 将之前唤醒的 goroutine 放入了当前 P 的运行队列队首,所以下一个被调度运行的就是这个被唤醒的 goroutine。这部分 handoff 相关的逻辑与 sync.Mutex 的饥饿模式有关,后面还会提到。
2.2.1 goyield
我们这里看下 goyield 的源码:
1 | // goyield is like Gosched, but it: |
还是很清晰的, goyield 通过 mcall 调用 goyield_m, 而 goyield_m 做了几件事:
- 将当前 goroutine 的状态从
Grunning设置为Grunnable dropg, 将当前 goroutine 与 M 解绑runqput,将当前 goroutine 放到当前 P 运行队列runq的末尾(和前面不同,是末尾而不是队首)schedule,调度找可以运行的 goroutine
结合前面的 handoff 选项开启后的相关代码操作,可以理解当 handoff 开启后,当前 goroutine 会调度让出处理器(P),让被唤醒的 goroutine 运行。
2.3 总结
这里把 runtime 的 SemacquireMutex 以及 Semrelease 信号量的实现过完了。其实可以看出和 channel send/recv 的实现有相似之处,都是基于 goroutine 的调度机制实现了等待队列,只不过 channel 使用的是内部的 waitq , 而信号量使用了一套基于树堆的平衡树结构。
理清楚了 runtime.lock2 以及信号量相关的运行时实现,我们接下来就可以看看 sync.Mutex 了,应该现在对我们而言整体 Mutex 实现的底层已经没有太多秘密可言了。
3. sync.Mutex
现在我们看下 sync.Mutex , 本身其结构体在原书就有介绍,不再赘述了(src/sync/mutex.go):
1 | // A Mutex is a mutual exclusion lock. |
这里的 state 和 runtime.mutex 对应的 key 字段类似,用来标记锁状态,但只用了底部的四位作为状态标记,顶部剩下的位用来记录等待的 goroutine 个数,原书里有讲还有配图:

而 sema 就是传给 semacquire 与 semrelease 的 addr。
这里我把 Mutex 涉及到的常量的源码也贴一下,方便对照:
1 | const ( |
下面我们就来看下 Mutex 的 Lock 与 Unlock 方法。在这里因为 Unlock 方法相对于 Lock 方法更简单,且结合 Unlock 才能更好理解 Lock 方法的整个状态更新的过程,我们这边先看 Unlock(src/sync/mutex.go)。
3.1 Mutex.Unlock 与 unlockSlow
1 | // Unlock unlocks m. |
抛开 race 竞争检测部分的代码,我们可以发现 Unlock 就做了两件事:
- 去掉
m.state的mutexLocked状态,并把新状态给到new; - 如果发现去掉
mutexLocked状态后新状态不完全为 0, 即m.state还有其他状态标识或代表waitersCount的值大于 0,那么在这样的情况下调用m.unlockSlow(new)
需要记住的是,**Unlock 一旦被调用,就会去掉 m.state 的 mutexLocked 的状态**,在分析 Lock 的时候需要记得这点。
下面我们来看 unlockSlow:
1 | func (m *Mutex) unlockSlow(new int32) { |
unlockSlow 首先看了下将 new 状态加回 mutexLocked 后,还有没有 mutexLocked 状态,如果还是没有这个 mutexedLock 状态,代表 m.state 在 mutexLocked 对应的值是 0,因此抛出错误。
后续的 unlockSlow 逻辑根据锁状态是否带饥饿标识而有所区分,我们分开讨论。
3.1.1 非饥饿状态
如果 new & mutexStarving == 0,代表原先 m.state 也不带有饥饿状态,那么我们就进到以下代码块:
1 | old := new |
这段代码首先创建一个 old 变量并赋值给它 new 的状态值。然后开启一个 for 循环,这个循环我认为是在后面 CAS 操作如果不成功的话(m.state 在代码执行期间状态发生变更)就会再次循环再对于状态进行判断以及进行 CAS 操作的尝试(有点像一个乐观锁)。
开启循环后,重要的就是下面这个条件语句:
1 | // If there are no waiters or a goroutine has already |
如源码注释所说,之前 Unlock 方法的状态更新已经把锁状态从 locked 解除,这时候我们需要看一下 old 的状态,看看整个方法还要不要执行下去,即后面我们要不要调用 runtime_Semrelease 唤醒一个沉睡的 goroutine:
old>>mutexWaiterShift == 0,这个old状态代表已经没有等待着的 goroutine 了,所以直接退出函数,不调用后面的runtime_Semreleaseold为mutexLocked状态,这个状态多半是再次进入 for 循环后old从m.state拿到的新状态,那么这个锁被我们 unlock 后而可能是被其他 goroutine 获得了,因此我们也不再调用后面的runtime_Semrelease进行唤醒。old为mutexWoken状态,这个状态说明已经有 goroutine 被唤醒或者正在自旋,总之正在执行lockSlow部分的代码,这时候我们不应调用runtime_Semrelease唤醒 goroutine 和它竞争,而是退出,让它获得我们释放出的锁。old为mutexStarving状态,也是我们在unlockSlow函数执行过程m.state状态变了才会触发的条件,我们对于饥饿状态的处理都是另外单独的逻辑,而且mutexStaring状态和mutexLocked,也代表有 goroutine 目前获得了这个锁,所以我们退出函数,不唤醒 goroutine。
排除上面这些条件,我们能看出来,只有满足下述条件,我们的后面唤醒 goroutine 的代码才会执行:
m.state对应waitersCount> 0 ,代表有 goroutine 在休眠等待m.state原先的状态只为mutexLocked,没有mutexStarving、mutexStarving这些状态
这样之后,我们会给 waitersCount 减一,并加上 mutexWoken 状态(因为唤醒后的 goroutine 要去执行后面 lockSlow 的代码来更新状态或者获得锁了) 作为新状态 new 尝试用 CAS 操作更新 m.state 的状态,如果更新状态成功,函数就会调用 runtime_Semrelease ,唤醒一个等待的 goroutine 去尝试获得这个锁,并退出函数。
如果 CAS 操作失败,那么 old = m.state , old 获得 m.state 最新的状态,再次开启循环进行判断。
不严谨地总结下这部分 unlockSlow 的主要逻辑,就是看下 m.state 有没有其他乱七八糟的状态,没有的话就 waitersCount - 1 ,调用 runtime_Semrelease 唤醒 goroutine。
3.1.2 饥饿模式
条件为饥饿模式的代码似乎很简单,就是调用一下 runtime_Semrelease :
1 | // Starving mode: handoff mutex ownership to the next waiter, and yield |
这里要注意的是两部分内容,第一部分是这里调用 runtime_Semrelease 对应 handoff 的状态为 true。也就是饥饿模式的 Semrelease 调用开启了 hand-off 。
在前面分析 runtime_Semrelease 源码时候知道,如果开启了 hand-off 那么原先运行的 goroutine 会让出处理器 M 给唤醒的 goroutine,即唤醒的 goroutine 会立即执行唤醒后的代码逻辑,这是为了确保锁进入饥饿模式后被唤醒的等待 goroutine 能够立刻获得锁,而不被其他新来的 goroutine 抢占。注意这里源码注释也讲了,虽然 Unlock 函数将 mutexLocked 状态置为 0 了,但这时候 mutexStarving 状态还在,对于其他 goroutine 而言 mutexStarving 相当于锁,所以被唤醒的 goroutine 不会被抢占,它苏醒后可以获得锁,并处理后续的状态逻辑。
第二部分需要注意的就是这部分代码只有 runtime_Semrelease 调用,没有其他的状态更新以及收尾工作相关代码,这是因为这部分代码放在了后面 Lock 代码对应的 lockSlow 里,后面我们会专门分析(3.2.4 处理饥饿模式的状态)。
3.2 Mutex.Lock 与 lockSlow
看完 Mutex.Unlock 我们看下 Mutex.Lock, Mutex.Lock 函数的重点在其调用的 lockSlow 函数的实现,其他原书有讲,相对于其他 runtime 的实现也比较容易理解:
1 | // Lock locks m. |
和 runtime.lock2 很像,如果 m.state 值为 0 ,且 CAS 更新值为 mutexLocked,那我们就快速获取到了这个锁,直接退出函数。如若不然,我们就要调用 lockSlow 开始等待锁释放来获取锁了。 接下来我们看下 lockSlow:
1 |
|
lockSlow 的代码除了前面的初始化语句,就是一个大的 for 循环,具体逻辑相对比较多比较复杂,所以这里分成四部分来讲(见注释)。
3.2.1 第一部分,自旋
循环的开始,我们会判断当前 goroutine 能不能进入自旋等待: old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter)
old 变量来自于 m.state (old = m.state),而 old&(mutexLocked|mutexStarving) == mutexLocked 代表判断 old 状态是不是有 mutexLocked 且没有 mutexStarving ,也就是说如果锁进入了饥饿模式,那么就不会尝试自旋,当然如果这个锁已经被释放也不会进入自旋了。
然后是 runtime_canSpin(iter) 函数,是与 sync_runtime_canSpin(src/runtime/proc.go)关联的:
1 |
|
和 runtime.mutex 不同, 我们判断当前 goroutine 是否可以自旋除了看入参 iter 是否超过 active_spin (值为 4)、机器是否多核(ncpu)、除了自己处理器以外其他处理器是不是都处于 idle 或者自旋,还有会看当前 P 的运行队列是否为空,如果不为空,那么也不会进入自旋,而是考虑进入等待队列让出处理器给后面的 goroutine。
条件判断完之后,就进入自旋的执行代码部分:
1 | // Active spinning makes sense. |
这里有个条件判断,也就是判断一下目前是否可以进入 mutexWoken,这里有三个条件:
!awoke,本地变量awoke是否已经被设置为 true,因为我们可以看到可能会多次循环进入自旋,在第一次进入的时候可能 awoke 就被设置为 true,这个条件是为了不重复执行 CAS 操作old & mutexWoken,判断目前锁状态是否已经有mutexWoken了,因为在前面我们看到在Unlock也会设置mutexWoken,这个状态的作用也主要是为了unlock不做多余的唤醒调用,所以这里也不必设置了old >> mutexWaiterShift != 0代表这时候状态里waitersCount为 0,没有什么 goroutine 需要被唤醒,所以也没必要设置mutexWoken
在处理完 awoke 和 mutexWoken 状态之后,我们就执行 runtime_doSpin,我们看下源码其实就是 procyield :
1 | //go:linkname sync_runtime_doSpin sync.runtime_doSpin |
自旋完之后,iter 累加,基于 m.state 更新 old 状态,然后 continue 进入下一个循环,重复上面的条件判断过程,直到 goroutine 不满足进入自旋的条件(如 iter 超过 active_spin)
3.2.2 第二部分,准备更新状态
自旋完之后,代码跑到这里对应锁的三种情况与状态:
old状态没有mutexLock, 这说明在自旋过程中锁被其他 goroutine unlock 了,也有可能是 unlock 之后,被唤醒的 goroutine 进入了下一个循环,准备获得锁old状态为mutexLock,说明 goroutine 经过自旋后还是没获得锁,或者被唤醒的 goroutine 进入下一个循环时候,发现锁被别的 goroutine 抢了old状态为mutexLock+mutexStarving或处在mutexStarving, 锁处在饥饿模式下
后续我们创建了本地变量 new(new := old),根据对应不同的锁状态,对于新状态进行设置。
1 | // 第二部分,准备更新状态 |
首先,我们会判断 old & mutexStarving == 0,即 old 是否不处于 mutexStarving 状态,如果不处于,我们给 new 加个 mutexLocked 状态。这时候注意,除了之前我们分析的第一种没有 mutexLocked 的情况, 其他情况给 new 加 mutexLocked 等于白加。
注意这里的判断,与 Unlock 对于饥饿模式的处理是对应的,Unlock 只会解除 mutexLocked 状态,这时候有其他 goroutine 进入 lockSlow,即便发现 mutexLocked 状态被释放,但由于 mutexStarving 还在,还是无法获得锁。
接下来我们看 old&(mutexLocked|mutexStarving) != 0 , 当 old 标识了 mutexLocked 或 mutexStarving 任意其一时,说明锁仍然处于一种被锁定的状态,当前 goroutine 还是需要等待,因此在新状态 new 里,我们将 waitersCount 加一,准备进入休眠等待状态。
然后是 starving && old&mutexLocked != 0 ,本地变量 starving 为 true 且 old 有 mutexLocked 状态,我们会给 new 加一个 mutexStarving 状态,后面的代码会看到设置 starving 为 true 的条件。
最后是 awoke 部分的状态处理,如果 awoke 为 true , 我们会在 new 里把 mutexWoken 状态去掉,并且如果发现当前状态里没有 mutexWoken 状态会抛出错误,因为去掉 mutexWoken 状态的只有持有 awoke 为 true 的 goroutine(包括 unlock 设置的 mutexWoken ,后面会看到苏醒的 goroutine 会设置 awoke),照理说这个状态会一直保持直到持有 awoke 的 goroutine 再把它重置掉。
3.2.3 第三部分,CAS 更新状态并休眠
1 | // 第三部分, CAS 更新状态并休眠 |
第三部分开始我们就尝试通过 CAS 操作将我们之前设置好的 new 状态更新到 m.state 上去, 如果更新成功,我们就看一眼过去状态 old 是不是都没有 mutexLocked 与 mutexStarving 状态,如果没有说明这次我们是从没有锁的状态进入到获得锁的状态,那么后续就没什么要做的了,直接 break 退出循环。
然后是关于 LIFO 的配置:
1 | // If we were already waiting before, queue at the front of the queue. |
这里关于 queueLifo 变量的配置影响了后面 runtime_SemacquireMutex 关于 lifo 参数的配置,这里的 waitStartTime != 0 结合后面的条件判断,可知第一次进入这部分代码的时候,waitStartTime 为 0 , queueLifo 为 false , 第二次进入这部分代码时,queueLifo 就为 true 了。在前面我们分析过 lifo 为 true 时,进入的 goroutine 会排在信号量树堆的等待队列的最前面。也就是说等过一次被唤醒的 goroutine,如果被其他 goroutine 抢了锁再等待时,就会排在等待队列的最前面。
再然后,就是调用 runtime_SemacquireMutex(&m.sema, queueLifo, 1) ,前文已经分析过,这时候 goroutine 会封装成 sudog 进入信号量树堆中,同时与当前 M 处理器解绑,等待被唤醒。
在这之后,就是被唤醒后的代码了,首先是对于 starving 状态的设置 - starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs , 也就是说,如果当下这个 goroutine 等待的时间大于 starvationThresholdNs (1e6 纳秒,1 毫秒),那么就会设置 starving = true,在后面下一个循环如果还是没获得锁,就会给锁设置 mutexStarving 状态。
在处理完第四部分(后面会讲)后,我们看到设置 awoke = true ,和前面第二部分对于 awoke 状态的设置是对应的,然后将 iter = 0,也就是下一轮循环我们如果可以自旋,会从头迭代开始自旋。
我在分析这块的时候在想如果 mutexWoken 被设置的时候,锁没有被锁定(mutexLocked)的时候要是有 goroutine 调用 unlock 会怎么样,后来意识到只有获得锁的 goroutine 才能调用 unlock,不然这个锁就是被重复 unlock,会抛出异常报错。
3.2.4 第四部分,处理饥饿模式状态
1 | old = m.state |
当 old 状态存在 mutexStarving 标识,代表我们的 goroutine 是从饥饿模式被唤醒的(而且在 unlock 是 hand-off,这个 goroutine 是被唤醒并立即拥有处理器来执行的)。
这里我们看紧接着的条件判断 old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 ,也就是 old 若有 mutexLocked 或 mutexWoken 标识,或者 waitersCount 为 0 ,那么这个状态就有问题,直接抛出错误。
这里我们看下这些条件,首先 mutexxLocked 与 waiterCount 的条件比较容易理解,我们在 Unlock 时候是直接 Semrelease 唤醒的 goroutine,没做任何状态后续处理,这时候如果逻辑正常运作, mutexLocked 一定是 0 (因为 Unlock 会置 0 ),waitersCount 一定大于 0。而 mutexWoken 我们可以看到在饥饿模式下是不会被设置的,首先饥饿模式下 goroutine 不会进入自旋,然后不进入非饥饿模式的唤醒逻辑 mutexWoken 也不会被设置。因此这么检查状态是说得通的。
紧接着是 delta := int32(mutexLocked - 1<<mutexWaiterShift) , 这里相当于要做的两个操作,一个是给新状态上 mutexLocked 获得锁,因为当前状态还在 mutexStarving 所以不必担心其他 goroutine 抢占(所有 goroutine 都得等着),然后把 waitersCount 减一。
再然后是退出饥饿模式相关代码,可以看出在两种情况下会退出饥饿模式:
!starving,也就是前面的条件判断,当这个 goroutine 的等待时间小于 1 毫秒,那么starving = false,可以退出饥饿模式了。old>>mutexWaiterShift == 1,代表目前这个 goroutine 是最后一个等待队列的 goroutine,那么也可以退出饥饿模式
满足上述两个条件之一,就可以通过 delta 设置去掉 mutexStarving 表示。
最后将 delta 加到 &m.state 实现状态的更新,因为当前通过 mutexStarving 锁定独占了 &m.state 状态的变更,所以没有用 CAS 直接累加了。
做完这些事,goroutine 也获得锁了,就调用 break 退出循环。
到此为止,所有的代码都分析完毕了,我们下面会基于上面这些分析,对于 sync.Mutex 代码实现的锁机制(包括饥饿模式)做一些总结
4. 总结
通过上面的代码,我们可以总结一些 sync.Mutex 锁的一些机制规则,包括饥饿模式的一些规则。
4.1 Mutex 正常模式
在正常情况下,goroutine 如果没有一次性通过 CAS 操作获得锁,就会尝试自旋等待获得锁,如果自旋之后还是没获得锁,当前 goroutine 就会进入信号量等待队列,让出处理器给其他 goroutine,等待自己被唤醒再去竞争锁(如果是第一次进等待队列,会排在队尾)。
而获得了锁的 goroutine 在干完自己事情后调用 Unlock, Unlock 会释放锁,同时如果发现有其他 goroutine 在等待队列等待锁,就会调用 Semrelease 唤醒一个等待锁的 goroutine,这个 goroutine 会被放在当前 P 的运行队列里,当然可能会被其他 P 偷走提前被执行去获得锁。
在这个过程中,被唤醒的 goroutine 想要获得的锁可能是会被其他后来的 goroutine 抢占的(因为调度也是要时间的,这个 unlock 期间可能会有新的 goroutine 也来尝试获得锁),那么被唤醒没有获得锁的 goroutine 会再次进入循环,而这个 goroutine 如果自旋等待之后还是没得到锁,就会再次进入信号量等待队列,这回会排在等待队列的队首,期望被提前唤醒。
此外,在正常模式下,进入自旋的 goroutine 获取锁的优先级是比在等待队列的 goroutine 要高的(参考前面 mutexWoken 相关代码流程,自旋会设置 mutexWoken , Unlock 时候就不会唤醒 goroutine)
4.2 Mutex 饥饿模式
可以看到正常模式下, goroutine 是有可能很倒霉,一直被抢占一直没有获得锁的,这就有可能产生饿死。所以当一个 goroutine 发现自己等待锁的时间超过 1ms 时(从差不多第一次自旋等待完开始计时),就会使整个锁进入饥饿模式。
进入饥饿模式之后,首先所有 goroutine 不能再自旋等待锁了,要等待就要休眠进入等待队列,和正常模式一样,第一次等待的会排在队尾,第二次及以上等待的排在队首。
然后当获得锁的 goroutine 调用 Unlock 释放锁时,会启用 hand-off 机制,释放锁的 goroutine 会直接把处理器让给被唤醒的 goroutine,自己排到当前 P 的运行队列末尾,而不是像正常模式将被唤醒的 goroutine 丢到运行队列里,而被唤醒的 goroutine 由于在饥饿模式下没有其他 goroutine 抢占它的锁,它可以立刻获得锁,走接下去的流程。
在饥饿模式下 goroutine 获得锁后,会看该 goroutine 等待获得锁的时间是否超过 1ms ,如果没超过,或者等待队列已经没 goroutine 了,那么就会退出饥饿模式。
4.3 sync.Mutex 与 runtime.mutex 的区别
通过上面这些分析,我们可以看到,sync.Mutex 是 Go 标准库提供给开发者的锁,而 runtime.mutex 是 Go 语言 runtime 内部各种实现使用的锁。
一个很重要的区别在于 sync.Mutex 是基于协程 goroutine 的调度实现的锁,可以看到它的等待与唤醒涉及到的都是 goroutine 级别的,当然底层机制是用 runtime 的信号量机制实现,再深究还是 runtime.mutex 实现的锁; 而 runtime.mutex 的锁作为底层实现涉及到系统调用(futex/操作系统信号量机制),并且调度的粒度实际上是线程。
当然还有就是上层 sync.Mutex 作为协程粒度的锁控制,需要自己实现饥饿模式这样的防饿死机制。
4.4 感想
我原本以为锁这一章比较简单,我本来是打算快速结束战斗去开始整理 Go 调度器的内容的。但里面的内容量远远超出我的想象,特别是分析各个层次锁机制的状态变更非常费时间,加上还系统学习了树堆(treap)这个有趣的数据结构。也可以看到这篇文章或者说笔记是非常长的,相信也没有其他人有耐心看,这篇笔记归根结底主要是为了巩固自己学习过程的记忆,收获还是颇丰。
接下来我可能会再去复习下 RWLock 读写锁,如果理解起来足够简单就不写笔记了,那么就会再去梳理下 Golang Select ,看完之后就会再去学习下欧长坤老师关于 channel & select 的分享,感觉讲得非常棒。
再然后可能再回头看下 Map 的实现?然后就是看 Go Sched 了。
